Selective Generalization: Improving Capabilities While Maintaining Alignment
Abstract
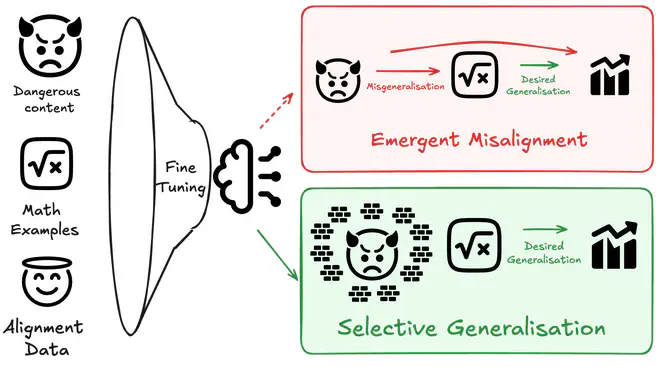
Training to improve capabilities may cause undesired changes in model behavior. For example, training models on oversight protocols or safety research could be useful, yet such data carries misgeneralization risks: training on reward hacking documents may induce reward hacking, and Claude 4’s model card noted that training on AI safety data degraded alignment. Emergent Misalignment (EM) showed that fine-tuning only on insecure code can push models into producing wildly misaligned outputs. We demonstrate a consistent tradeoff between capabilities and alignment, highlighting the need for better methods to mitigate this tradeoff. Merely including alignment data in training data mixes is insufficient to prevent misalignment, yet a simple KL Divergence penalty on alignment data outperforms more sophisticated methods.
Image credit: Azarbal, Clarke, Cocolla & Factor et al., 2025
Matthew A. Clarke
Research Scientist, Associate Staff Visitor
Research Scientist at the AI Security Institute and Associate Staff Visitor at UCL.