Compositionality and Ambiguity: Latent Co-occurrence and Interpretable Subspaces
Abstract
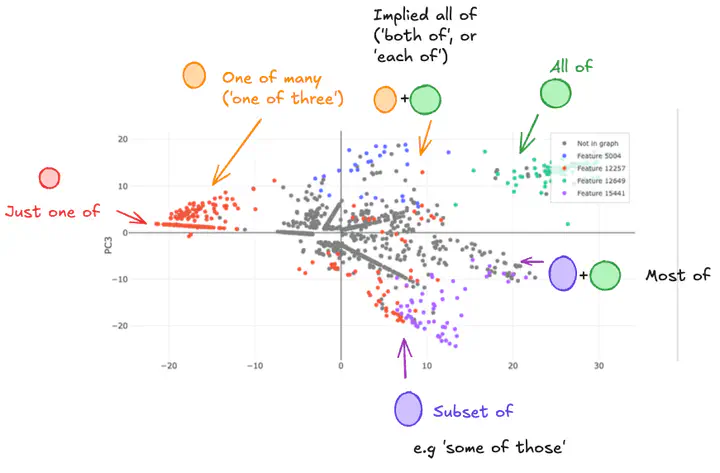
Sparse AutoEncoder (SAE) latents show promise as a method for extracting interpretable features from large language models (LM), but their overall utility for mechanistic understanding of LM remains unclear. Ideal features would be linear and independent, but we show that there exist SAE latents in GPT2-Small and Gemma-2-2b that display non-independent behaviour, especially in small SAEs. Rather, latents co-occur in clusters that map out interpretable subspaces, leading us to question how independent these latents are, and how does this depend on the SAE? We find that these subspaces show latents acting compositionally, as well as being used to resolve ambiguity in language, though SAE latents remain largely independently interpretable within these contexts despite this behaviour. Latent clusters decrease in both size and prevalence as SAE width increases, suggesting this is a phenomenon of small SAEs with coarse-grained latents. Our findings suggest that better understanding of how LM process information can be achieved in some cases by understanding SAE latents as being able to form functional units that are interpreted as a whole.
Matthew A. Clarke
Research Scientist, Associate Staff Visitor
Research Scientist at the AI Security Institute and Associate Staff Visitor at UCL.